🤷♂️ 엘라스틱 스택의 엘라스틱서치
엘라스틱 스택의 핵심 기술인 엘라스틱 서치를 제대로 분석
📌 목차
- 엘라스틱서치: 검색
- 쿼리 컨텍스트와 필터 컨텍스트
- 쿼리 스트링과 쿼리 DSL
- 유사도 스코어
- 쿼리
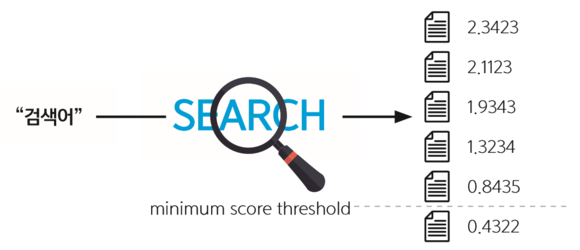
✔ 엘라스틱서치: 검색
- 엘라스틱서치는 전문 검색 기능을 시작으로 꾸준히 성장해 왔으며 다양한 검색 쿼리를 지원
- 텍스트, 숫자 데이터를 저장한 다음에 인덱싱을 마치면 쿼리를 실행하여 결과를 얻을 수 있다.
- 스코어링 알고리즘을 적용해 연관성이 높은 결과에 대한 제어가 가능하므로 대량의 데이터를 대상으로 빠르고 정확한 검색이 가능하다.
✔ 쿼리 컨텍스트와 필터 컨텍스트
유사 검색은 query context, 정확한 검색은 filter context 사용
쿼리 컨텍스트
질의에 대한 유사도를 계산해 이를 기준으로 정확한 결과를 먼저 보여준다.
필터 컨텍스트
유사도를 계산하지 않고 일치 여부에 따른 결과만을 반환
✔ 쿼리 컨텍스트와 필터 컨텍스트

'엘라스틱' 문자열을 검색하는 경우
- 필터 컨텍스트는 쿼리 스코어링을 생략하기 전체적인 쿼리 속도 향상 가능.
- 또한 캐시를 이용할 수 있다. (엘라스틱는 기본적으로 힙 메모리의 10% 캐시 사용)
✅ 쿼리 컨텍스트 실행
GET kibana_sample_data_ecommerce/_search
{
"query": {
"match": {
"category": "clothing"
}
}
}
- category 필드에 clothing로 매칭되는 document를 반환 해달라.
✅ 쿼리 컨텍스트 실행 후
- 3927개의 도큐먼트가 높은 스코어 순으로 정렬.
- 유사도 계산 알고리즘에 의해 가장 연관성 높은 도큐먼트 조회
- score 값이 클 수록 유사도가 높은 도큐먼트.
✅ 필터 컨텍스트 실행
GET kibana_sample_data_ecommerce/_search
{
"query": {
"bool": {
"filter": {
"term": {
"day_of_week": "Friday"
}
}
}
}
}
- 필터 컨텍스트는 논리(bool) 쿼리 내부의 filter 타입에 적용
- 과거 1.x 버전에서는 용어 검색, 용어 필터 처럼 필터 컨텍스트 구분, 현재는 구분 x
- 즉, 쿼리/필터 컨텍스트를 혼합해 사용하는 추세.
✔ 쿼리 스트링과 쿼리 DSL: 쿼리 스트링
엘라스틱 서치에서 쿼리 사용방식은 쿼리 스트링과 쿼리 DSL 존재
query string
# 한 줄정도의 간단한 쿼리에 사용
GET kibana_sample_data_ecommerce/_search?q=customer_full_name:Mary
- 간단한 쿼리를 한 줄에 작성하기에 가독성 :+1:
- 반대로 복잡한 쿼리는 가독성 :-1:
✔ 쿼리 스트링과 쿼리 DSL: 쿼리 DSL
query DSL
GET kibana_sample_data_ecommerce/_search
{
"query": {
"match": {
"customer_full_name": "Mary"
}
}
}
- REST API의 본문(Body) 안에 JSON 형태 쿼리 작성.
- 엘라스틱 서치의 모든 쿼리 스펙 지원, 복잡한 쿼리 구현 가능
- 단순한 쿼리는 굳이 Query DSL 사용할 필요가 없다. :sunglasses:
✔ 유사도 스코어
질의문과 도큐먼트의 유사도를 계산 표현하는 값, 스코어가 높을수록 :+1:
- 쿼리 컨텍스트는 엘라스틱에서 지원하는 다양한 알고리즘을 사용.
- 대표적으로는 BM25 알고리즘을 이요해 유사도 스코어 계산.
- explain keyword를 통해 어떤식으로 계산이 되었는지 확인 가능
✅ 설명(explain)이 포함된 쿼리 컨텍스트의 실행
위 쿼리는 Kibana console 창에서 직접 실행
GET kibana_sample_data_ecommerce/_search
{
"query": {
"match": {
"products.product_name": "Pants"
}
},
"explain": true
}
explain keyword
- 쿼리 내부 최적화 방법?
- 어떤 경로를 통해 검색이 되었는가?
- 어떤 기준으로 스코어가 계산되었는가?
✅ 스코어 알고리즘(BM25) 이해하기
스코어는 도큐먼트와 쿼리 간의 연관성 수치로, 값이 클수록 연관성이 높다는 것을 의미한다.
이 스코어를 계산하기 위해 사용되는 알고리즘이 BM25 알고리즘이다.
Elasticsearch 5.x 버전 이전에는 TF-IDF 알고리즘을 사용 했으나 5.x 버전부터 BM25 알고리즘을 기본으로 사용한다.
BM25 ( 척도 || 근거 )
- 대표적으로 검색, 추천에 많이 사용
- 검색어가 문서에 얼마나 자주 나타나는지
- 검색어가 문서에서 얼마나 중요한 내용인지
✅ IDF 계산 ( Inverse Document Frequency )
- 특정 용어가 얼마나 자주 등장했는지를 의미하는 지표.
- 관사('to', 'the'), 접속부사('그리고', '그러나') 같은 용어는 실제 의미가 없는 단어
- IDF는 Document에서 발생 빈도가 적을수록 가중치를 높게 준다. ( 빈도의 역수 )
IDF 계산식
"idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:"
- 변수 N, n만 알면 IDF를 구할 수 있다
✅ IDF 계산 ( Inverse Document Frequency )
{
"value": 7.1974354,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 3,
"description": "n, number of document containing term",
"details": [ ]
},
{
"value": 4675,
"description": "N, total number of document with field",
"details": [ ]
}
]
},
- n : 검색했던 용어가 몇개의 도큐먼트에 있는가?
- N : 해당 인덱스의 전체 도큐먼트 수 (kibana_sample_data_ecommerce)
✅ TF 계산( Term Frequency )
- 특정 용어가 얼마나 많이 등장했는지를 의미하는 지표.
- IDF와는 반대로 특정 용어가 많이 나오면 중요한 용어로 인식하고 가중치 :point_up:
TF 계산식
"tf, compute as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:"
- 변수 freq, k1, b, dl, 'avgdl'만 알면 TF를 구할 수 있다.
{
"value": 0.52217203,
"description": "tf, compute as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 1.0,
"description": "freq, occurences of term within document",
"details": [ ]
},
{
"value": 1.2,
"description": "k1, term saturation parameter",
"details": [ ]
},
...중략
]
},
- freq: 도큐먼트 내 용어가 나온 횟수
- k1, b: 알고리즘 정규화를 위한 가중치
- dl: 필드 길이
- avgdl: 전체 도큐먼트 평균 길이
✅ 최종 스코어 계산식
"description": "score(freq=1.0), computed as boost * idf * tf from:",
"details": [
{
"value": 2.2,
"description": "boost",
"details": [ ]
}
]
- 최종 스코어는 boost(고정값=2.2) _ idf _ tf 다.
✔ 쿼리 ( 엘라스틱 서치는 검색을 위한 쿼리를 지원 )
리프 쿼리
특정 필드에서 용어를 찾는 쿼리
- 매치(match) 쿼리
- 용어(term) 쿼리
- 범위(range) 쿼리
복합 쿼리
쿼리를 조합하여 사용하는 쿼리
- 논리(bool)쿼리
리프 쿼리 중 전문 쿼리(full text query)와 용어 수준 쿼리(term level query) 비교
✅ 리프 쿼리 - 전문 쿼리, 용어 수준 쿼리
전문 쿼리
전문 검색을 하기위해 사용이 된다.
- 검색을 할 필드는 인덱스 매핑 시 텍스트 타입으로 매핑해야 한다.
용어 수준 쿼리
정확히 일치하는 용어를 찾기위해 사용이 된다.
- 인덱스 매핑 시 필드를 키워드 타입으로 매핑해야 한다.
- 위 부분은 권장 사항이다
✅ 전문 쿼리 동작 방식
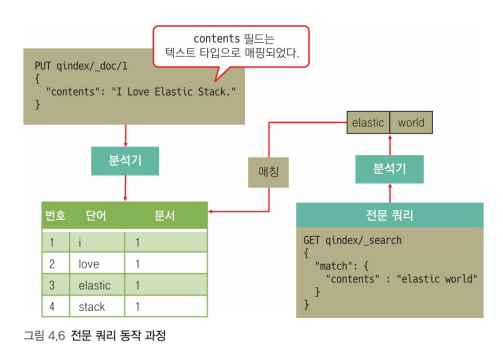
- match query의 생성과 조회 메커니즘
- match query는 구글, 네이버에서 검색어를 이용해 검색하는 방식을 연상
- 종류: 매치쿼리, 매치 프레이즈 쿼리, 멀티 매치 쿼리, 쿼리 스트링 쿼리 존재
✅ 용어 수준 쿼리 동작 방식

- Term Query의 생성과 조회 메커니즘
- Term Query는 전문 쿼리와 달리 정확한 용어를 검색할 경우 사용한다
- 날짜, 숫자, 범주 형 데이터를 정확하게 검색할 시 사용, RDB의 WHERE절과 비슷
- 종류: term Query, terms Query, 퍼지쿼리 존재
✔ 전문 쿼리 - 매치 쿼리
- 전문 쿼리의 가장 기본이 되는, 대표적인 전문 쿼리
- 전체 텍스트 중 특정 용어(Term)이나 용어들(Terms)을 검색 시 사용
- 매치 쿼리를 사용 하려면, 검색하고 싶은 필드를 알아야 한다.
- _mapping api 사용
✅ 하나의 용어 검색하는 매치 쿼리 예제
GET kibana_sample_data_ecommerce/_search
{
"_source": ["customer_full_name"],
"query": {
"match": {
"customer_full_name": "Mary"
}
}
}
- customer_full_name 필드에서 'Mary'라는 용어가 있는 Document 검색 요청
- 일반적인 분석기라면 => Mary => mary로 토큰화
- mary가 포함된 모든 Document :mag:
✅ 복수 개의 용어 검색하는 매치 쿼리 예제
GET kibana_sample_data_ecommerce/_search
{
"_source": ["customer_full_name"],
"query": {
// or: 토큰 간의 공백은 or로 구분
"match": {
"customer_full_name": "mary bailey"
},
// and
"match": {
"customer_full_name": {
"query": "mary bailey",
"operator": "and"
}
}
}
}
- 분석기에 의해 ['mary', 'bailey']로 토큰화 된다.
- 매치 쿼리에서 용어들 간 공백은 OR로 인식
✅ 그 외의 매치 쿼리 및 용어 쿼리 설명
매치 프레이즈 쿼리
- 구(동사가 아닌 2개 이상의 단어가 연결된 단어) 검색 시 사용 (순서도 맞아야 한다)
용어 쿼리
- 용어 수준의 대표적인 쿼리
- 분석기에 의해 토큰화가 안된다. 대소문자까지 정확하게 맞아야 검색.
✅ 그 외의 매치 쿼리 및 용어 쿼리 설명
범위 쿼리
- 특정 날짜 및 숫자의 범위를 지정해 범위 안에 포함된 데이터 검색
- 날짜/숫자/IP 타입만 가능, 문자형 키워드 타입은 불가능
논리 쿼리(Bool 복합쿼리)
- 논리 쿼리는 복합 쿼리로 앞에서 배웠던 쿼리를 조합 가능.
💥 논리 쿼리(Bool 복합쿼리) 부연 설명
- must
- 쿼리가 참인 도큐먼트 검색.
- 복수의 쿼리 실행 시 AND 연산.
- must_not
- 쿼리가 거짓인 도큐먼트 검색
- should
- 검색 결과 중 이 쿼리에 해당하는 도큐먼트 스코어를 높인다.
- 쿼리가 참인 도큐먼트를 검색, 스코어 계산은 안함.
참고 자료
'Elasticsearch > Elasticsearch - 사내 스터디' 카테고리의 다른 글
| [ES 사내 스터디] 엘라스틱스택 4회차 사내 스터디 (0) | 2023.04.25 |
|---|---|
| [ES 사내 스터디] 엘라스틱스택 2회차 사내 스터디 (0) | 2023.04.25 |
| [ES 사내 스터디] 엘라스틱서치 1회차 사내 스터디 (0) | 2023.04.24 |


